Markus Liedl - Deep Learning Development and Consulting
My name is Markus Liedl. I'm working since 20 years in the software industry. I'm doing backend and frontend development and since five years also machine learning.
Deep learning is a great development and a great chance. Already now, but even more so in the future, businesses who know to employ it will have a strong advantage.
I'm offering consulting and development for the Machine Learning aspects but also the wider spectrum of problems that need to be solved to get products successfully and in-time to the clients.
I have applied Deep Learning in many different settings, see below for the projects I was involved in.
You can reach me at markus.liedl.training@gmail.com
Or get a 30 minutes free consultation at +(49)1511 4422353
Jeeves' eyes - Minibar Robot - early 2018
 I employed a single shot multi-box detector to localise snacks and drinks in monocular snapshots. The same single forward pass also computed the boxes class. Regularisation and data augmentation were important due to tagging costs. For robotise
I employed a single shot multi-box detector to localise snacks and drinks in monocular snapshots. The same single forward pass also computed the boxes class. Regularisation and data augmentation were important due to tagging costs. For robotise
predict contract cancellations - late 2018

Based on historic data I designed a pre-processing pipeline and a neural network that predicted how likely a certain customer will cancel her contract. The company provides communication services to millions of customers daily.
Reducing customer churn has become a task of utmost importance for telecommunication providers. The markets mature and competition presence increases to unprecedented levels. Many service providers transition from a world of aggressive customer acquisition to a much more difficult world of customer satisfaction and retention.
Board game Go
I've re-implemented AlphaGo Zero on simplified rules.
The simplifications are (1) a much smaller board size and (2) to stop the game when
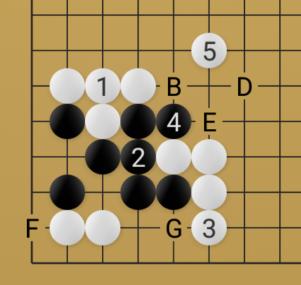 any player kills the first stone. These changes make the game finish in much fewer
steps than a regular game of Go. This time I used Cuda, C++ and cudnn directly
without any deep learning framework.
any player kills the first stone. These changes make the game finish in much fewer
steps than a regular game of Go. This time I used Cuda, C++ and cudnn directly
without any deep learning framework.
A few years earlier, 2015, it was already well documented to use convolutional networks to predict move probabilities for Go. I've made such a network in Theano - training on many professional game records. One year later I used the predicted move probabilities to suggest moves in my Go training app Guess the Move (Android Play Store)
leukemia - mid 2018
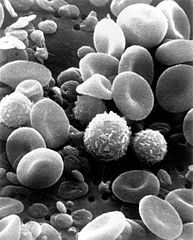 I created a neural network that predicts
how probable a patient suffers from leukemia and also which specific leukemia sub-class.
I created a neural network that predicts
how probable a patient suffers from leukemia and also which specific leukemia sub-class.
The networks input came from flow cytometry measurements. In general flow cytometry applied to leukemia measures the light emitted by fluorescent markers attached to white blood cells. The challenge in this project was that these measurements are very noisy. image credits
{kind=link}
unsupervised facial landmarks - mid 2019
I re-implemented the paper Unsupervised Learning of Object Landmarks through Conditional Image Generation by T. Jakab. Supervised landmarks are "interesting points" in images. In portraits that's normally eyes, nose, mouth, chin and so on. The model described in the paper is unsupervised though, so it decides itself which points are interesting. It converges to its own set of landmarks, e.g. just above the left eye, just a bit right from the nose. But the essential is that the discovered landmarks are consistent and could be used to regress other sets of landmarks, as described in the paper. I didn't do that, but I verified the information contained in the unsupervised landmarks by generating faces conditioned on the unsupervised landmarks alone. That's not a prove that the landmarks are "consistent", but it shows the amount of information contained in the landmarks. I decided to use 15 landmarks in these experiments.
The paper describes an interesting bottleneck layer. Overall it is in the category "train a model that repairs what you deliberately destroyed in the data", but not the way denoising autoencoders work. They receive only one input. The generator described in the paper is: Reconstruct an image given a vaguely similar image and precise landmarks. The "precise landmarks" are determined by another model that is trained at the same time, together with the generator.
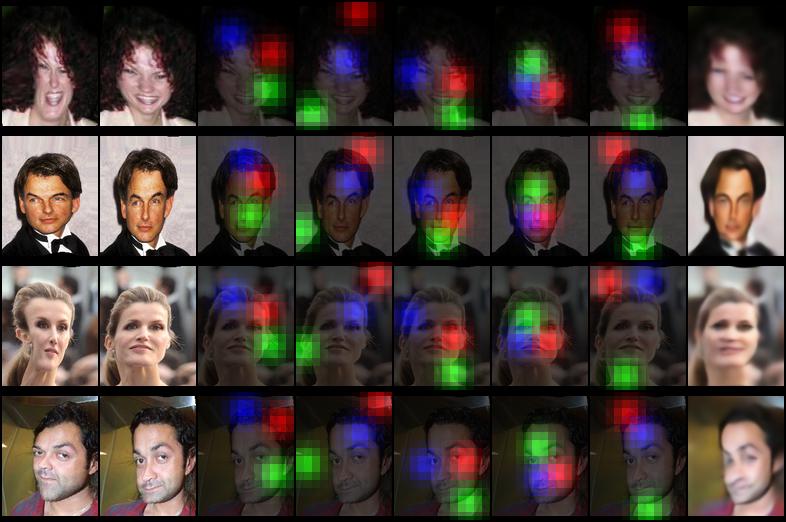 The unsupervised landmarks: The training goal is to generate an image (last column) that looks like the image in the second column given only the first column and the landmarks from the second column.
The unsupervised landmarks: The training goal is to generate an image (last column) that looks like the image in the second column given only the first column and the landmarks from the second column.

Reconstructions based on landmarks alone: These reconstructions are "generic" since their only input is the landmarks from the detector trained in the first step. This is an experiment to see how much information is contained in the landmarks. Head rotation is often times correct, also general shape of the face, often times the lightning, but not skin color or wrinkles. I am still asking myself how this generator can produce the correct background shade.
localize dancers in youtube videos - late 2017
To prepare for another object detection project I implemented a convolutional network to detect dancers in youtube videos. It is a single shot multi-box detector. That means it only needs one (computationally expensive) forward pass through the CNN to detect dancers of different sizes. I only used one single box aspect-ratio since that is good enough to detect dancers and it simplified a few things. Data augmentation was again important. This time with elastic transformations.
interactive deep learning demo - early 2018
I made an interactive deep learning demo. The idea was to not spend any time tagging the objects, but to simply take all pixels that were different from the background! Then only a name for the class needs to be entered. I used multiple web cams to capture every object from multiple perspectives. After a few photos the training can be started and finally the net can be tested. I've used the deep learning framework PyTorch. The UI was made with python GTK.
task time prediction - 2016
Workerbase offers a "industry smartwatch" to better organise workers. One of the many things I was building for them is a module that learns and predicts in real-time when a certain task will be finished. A task consisted of multiple sub-tasks and the prediction was the sum of the time distributions per sub-task. We assumed that all sub-tasks are independent. For workerbase.com
scratch removal in portrait images - late 2018
To prepare for another potential project I've used the CelebA dataset to train a deep neural network to reconstruct missing pixels. I'm assuming the detection of these missing pixels has already happened.

The columns are: Original image, missing pixels, naive repair, deep learning repair.
If you look very close you can see that the deep learning repair is often much better then the naive repair. Except, maybe, a few areas at a more global scale, for example the nearly completely missing eye.
I'm not touching advanced image inpainting ideas like adversarial nets, this is just per pixel mean squared error loss on a very high capacity ResNet. I've used the deep learning framework PyTorch, then re-implemented all in tensorflow, just to see that there is no difference.
split mixed music into instruments and voices - late 2018
Finally I'm reporting about an experiment that worked out worse than I hoped. I tried to split a mixed audio track into its constituent voices: Drum, bass, piano, lead vocals. The network only got the mixed audio as input and should reconstruct the tracks.
So the neural network had to learn which frequencies and modulations were characteristic for each voice. The problem is underspecified, since the process of mixing looses information.
I feel disappointed about the results. Listen for yourself:
In these samples you hear: Extracted drums, extracted bass, extracted piano, extracted lead vocals and finally the original mixed sound.
The neural net achieves to amplify the fitting frequencies and reduce the non-fitting frequencies, but still, the other voices show through clearly.
smart phone scratch detection PoC - 2018/2019
 Another company is working on a project in which they need to find out
the approximate (monetary) value of used smart phones.
I'm supporting them with an active learning system to mark scratches
on smart phone photos.
Another company is working on a project in which they need to find out
the approximate (monetary) value of used smart phones.
I'm supporting them with an active learning system to mark scratches
on smart phone photos.
We decided a great goal could be to classify each pixel of a smart phone photo into two classes: intact or scratch.
The active learning system is pre-trained in a supervised way with a few segments the team tagged on labelbox. Then the active learning starts: The photos are searched for pixels that the neural network is most uncertain about. These are the pixels presented to the user to tag. That way the users don't tag random pixels but those pixels that add most predictive power!
It's architected as a web service so users can tag remote and concurrently. I've used the python flask server, a webservice approach und react.js for the UI.
color reconstruction in portrait images - late 2017
I've used the CelebA dataset again to repair perturbed portraits. This time I blurred the photos, turned them grayscale, and modified the brightness randomly. The repair network was the generator in an adversarial setting. Beside a per pixel MSE loss I've mixed in the backpropagated gradient from a discriminator network.
The repair network didn't generate the whole image but the residuals to the low quality version.

The columns are: original image, perturbed image, repaired image.
The neural network tries its best to reconstruct the original images, based on the blurry, low quality images alone. Often times it is less fancy in the choosen colors.
Click here for more examples: (1) (2) (3) (4)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Many of the images are repaired multiple times, since the repair process is underspecified: It is adding information to the image and one can do it in different ways.
RL with Proximal Policy Optimization - early 2019
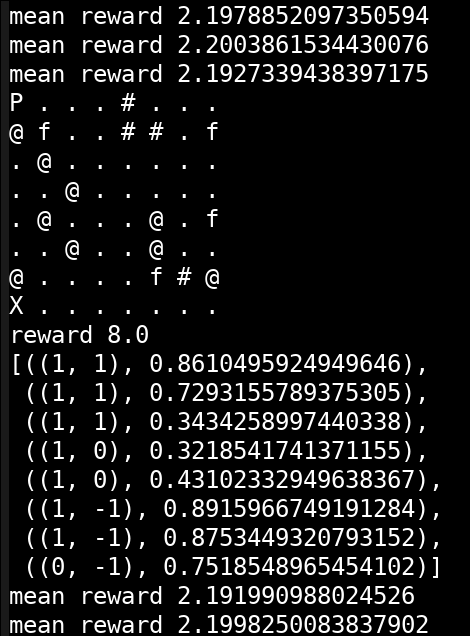
For my own edification I implemented the PPO Reinforcement Learning algorithm. It can be seen as an "accelerated" variant of the classic REINFORCE with baseline algorithm.
I've thrown it at a labyrinth problem. The agent views the 8x8 labyrinth from above, without any fog-of-war or occlusions.
P is the player. X is the goal. @ are the traps. f is food, and # are walls. Reaching the goal gives 10 score. Every collected food 0.5. Hitting a trap gives -10 reward and ends the episode.
Like in many Reinforcement Learning settings the agent behaves fully random in the beginning. That means, initially, only very few percent of the simulations reach the goal. Yet the algorithm learns to better and better collect more reward.
I've compared the PPO algorithm with REINFORCE and REINFORCE with baseline. The results showed clearly that PPO converges fastest.
Also, that batch normalization is a great advantage, esp. when using convolutions as the first two layers.
face interpolation - early 2018
Most of the time deep learning is applied to supervised learning. That means you specify manually what the output for every input should be. That's where currently the best results are achievable.
A lot of research is happening in other regimes, for example Generative Modelling. Adversarial networks showed the large potential. Generative Modelling is "digesting" data in such a way that random examples can be generated from a model.
I've implemented Generative Latent Optimization (GLO). It is like the decoder part of an auto encoder. The individual images codes are optimized via backpropagation through the decoder, i.e. the derivative of the per pixel loss with respect to the input code.
A possible use-case could be to meaningfully interpolate images.

crop fashion images - mid 2017
Lot's of fashion images are available on the web. I used deep learning to crop background away from fashion images. Here I learned an over-crop detector. It's single output was always 0.0 except when it detected that too much was cropped from any side. Then it gave 1.0. Again data augmentation and batch normalisation was important.
It crops images iteratively. It needs many neural network evaluations to detect from which sides it can still crop a few pixels, so it works much slower than a single shot detector.


The images show the data augmentation: The contents are heavily deformed but the content borders are carefully tracked.
Contact
I have great experience in applying Deep Learning to real world problems.
Let's talk about your idea!
Contact me at markus.liedl.training@gmail.com or +(49)15114422353